BigQueryを使い倒す会代表のkyontanです.今回は実用性低めな分野で BigQuery を1万倍有効活用する方法……ではなく延々とBigQueryがお得だという話をします.
今回ご紹介するテクニックを意味不明に活用することで,18.2GBのスキャン(10円程度)で2301億行の一時テーブルを作って集計することが可能です.便利ですね.ちなみに私は12桁の数字を突然見て混乱しました.
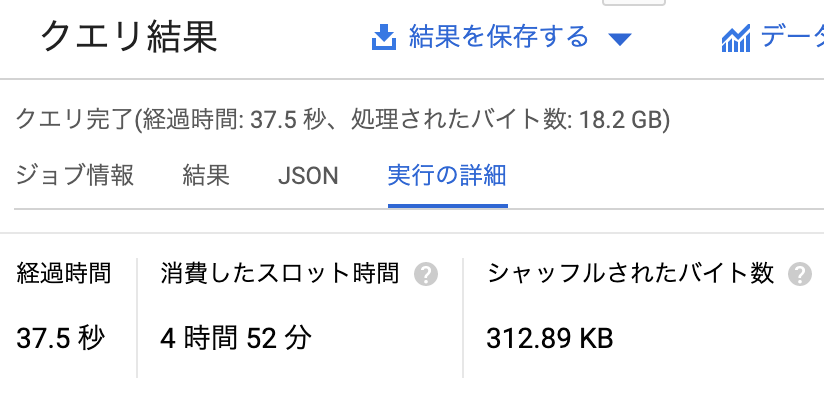 ちなみに上のクエリは37.5秒で帰ってきましたが,内部では4時間52分のCPU時間を使用したようです.つまり,単純に計算すると約500スレッドが並列して走っていたようです.すごいですね……
ちなみに上のクエリは37.5秒で帰ってきましたが,内部では4時間52分のCPU時間を使用したようです.つまり,単純に計算すると約500スレッドが並列して走っていたようです.すごいですね……
(注: この記事は実用性皆無です.ごく一部を除き,一般の分析用途でBigQueryを使用するユーザにはなんの利もありません)
他にも,1TB超えのデータをシャッフルすることもあり…… (シャッフルという概念は一般的なRDBMSにはなく,後述するMapReduceが持つ特徴の一つです)
1TBのデータをシャッフルできるの異常じゃないですか? DC内ネットワークすごいですね.

並列度が高いクエリだと1週間どころか2週間を超えるCPU時間を1発のクエリで使うこともあります.
 さて,BigQueryのコストはスキャンするデータ量に依存します.そのため,一般的なログ分析基盤でコスト削減のためにスキャンする列を減らしたり,時系列でパーティショニングして必要な分だけスキャンする手法が取られますが,こういった話はありふれているので割愛します.
さて,BigQueryのコストはスキャンするデータ量に依存します.そのため,一般的なログ分析基盤でコスト削減のためにスキャンする列を減らしたり,時系列でパーティショニングして必要な分だけスキャンする手法が取られますが,こういった話はありふれているので割愛します.
ここでの目的はスキャン量を増やすこと無くスロット時間(CPU時間)を増やすことであり,これにより同じコストでより多くのCPUを使いたいということです.とにかく多くのリソースを使うことが快楽に繋がります.
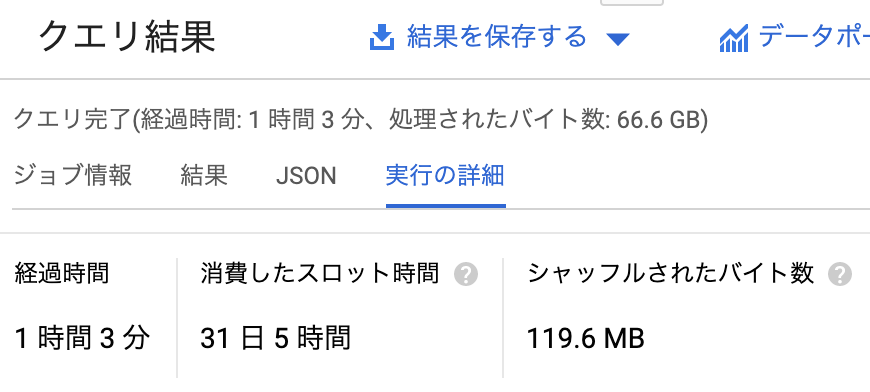
実際,上の図では31日と5時間のCPU時間をわずか66.6GBのスキャンで消費することに成功しています.
BigQueryは執筆時点で1TBスキャンするコストが$5ですから,66.6GBのスキャンはわずか30円程度です.30円でGCPのサーバを1ヶ月分動かせると考えるとお得な気がしませんか?
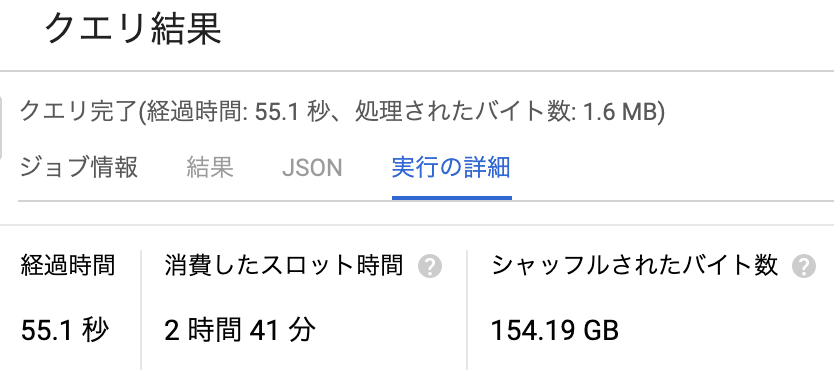
コストパフォーマンスを突き詰めていくと,1.6MBのデータから2時間41分のCPU時間を消費することもできます.
BigQueryは10MB以下しかスキャンしなかった場合には,10MBへ切り上げた上で課金の計算がなされますが,10MBスキャンしたところで掛かるコストは$0.00005 ですから,これは実質無料です.
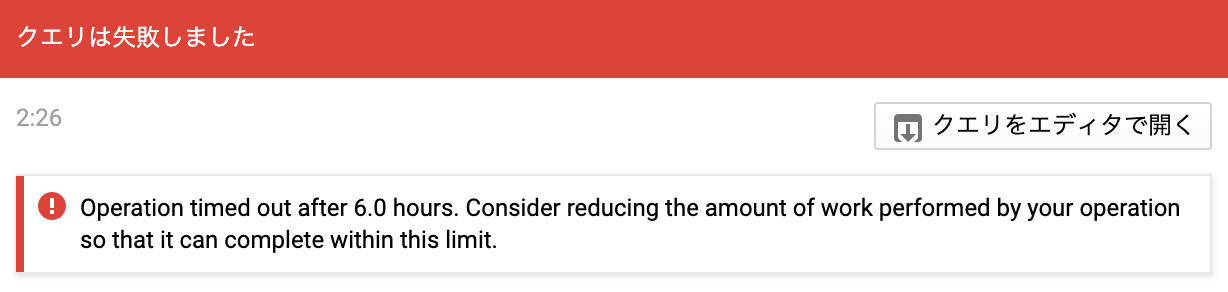
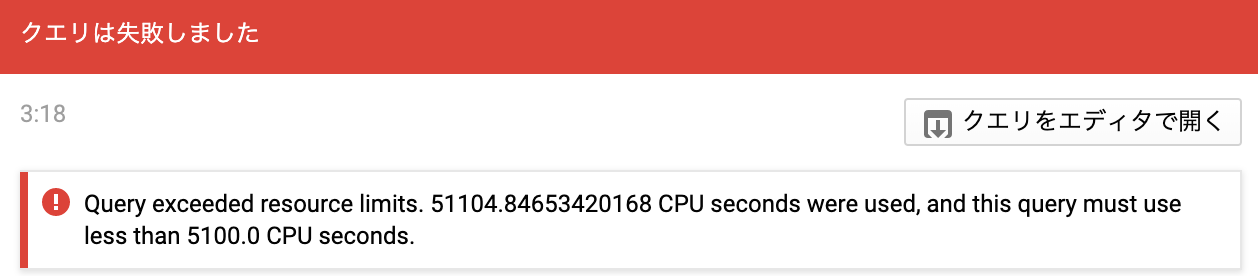
一方で,複雑なクエリを叩くと実際長い時間がかかることがあります.このとき,BigQueryではクエリのタイムアウトが6時間と定められているため,これを超えるとクエリが強制終了させられます.

{kind=link}
さて,我々は賢いので(?) BigQueryの内部アーキテクチャを攻略することで可能な限りこういった中断系エラーを避けつつ安価にクエリする方法を試すことができます.
BigQueryはSQLが使える分析特化のDBではありますが,中身はMapReduceだと推測され,実際クエリプランを見るとそれっぽい様子を垣間見ることができます.
MapReduceといえばHadoopやSparkが有名ですが僕は触ったことがありません.安易に解釈すると大量のマシンにデータをバラ撒いてジョインして適当に集計する,みたいな感じでしょうか.そのうち原論文をちゃんと読みたいですね.
BigQuery公式でも述べられていますが,クエリを高速に実行するためのキモはいかにうまく分散させるかに掛かっています.CPU時間を稼ぎつつ実時間を抑えるためにはこの並列数を上げるためのクエリ書換が重要になります.
今回私が実行したかったクエリは約1万行のテーブルを2重に自己結合するクエリでした.イメージとしては下のようなクエリになります.
単純にINNER JOINを2回書けばよいのですが,計算量は単純計算で1万の3乗,1兆回のループが発生します.終わりません.
SELECT *
FROM some_table src
INNER JOIN some_table a
ON ...
INNER JOIN some_table b
ON ...
実際にはON句での絞り込みがあるので結果セットは数分の一(それでも数千億ありますが)になるのですが,こんなクエリを素直に書いても全然スケールしません.
これは,行数が少ないテーブルのINNER JOINはあまり並列数を上げて実行してくれない現在のBigQueryのクエリ計画エンジン(?)の特性に思えます.
ちなみに BigQuery だと WITH句を使って一時テーブルの見た目をした何かを作ることができますが,これは実行プランには影響がありません.
WITH some_table_joined AS (
SELECT *
FROM some_table src
INNER JOIN some_table a
ON ...
)
SELECT *
FROM some_table_joined
INNER JOIN some_table b
ON ...
対策として,まず自己結合を1回した一時テーブルを作り(数千万行)クエリをし,その結果テーブルに対して再度自己結合を掛けるクエリを書いたところ500スロット並列で動くことを確認しました.具体的にはクエリを次の2つに分割することになります.
-- create some_table_joined
SELECT *
FROM some_table src
INNER JOIN some_table a
ON ...
-- join some_table_joined and some_table
SELECT *
FROM some_table_joined
INNER JOIN some_table b
ON ...
元の1万行のデータは高々数MBしかないため,これを2重結合するクエリが動けば実質無料になるのですが,これはうまく行かず,結局自己結合した一時テーブルのスキャンに数十円程度掛かりました.それでも安いのですが……
ちなみにここで注意すべきこととして,ストレージ課金があります.BigQueryのストレージは安価とはいえ,3ヶ月以内に変更されたデータに掛かる料金,つまりActive Storageは $0.020/GB です.中間テーブルを作ってクエリが終わり,使いみちがなくなったら不要なテーブルを削除しましょう.
(実際には BigQuery でクエリしたときに勝手に作られる結果用の一時テーブル(数時間しか有効期限がない)は課金されないような気がします.僕は実験が日をまたぐこともありますし,とりあえず名前を付けてテーブルに保存していたので消す必要がありました)
他にも,やはり数千万行を超えるデータのソートは苦手なようで,なかなか苦労しました.結局PARTITION BYの中でソートをして成功したことは数えるほどしかありません.今回のケースでは諦めてMIN, MAX関数に逃げてしまいましたが,本来は一時テーブルをもう一度作らないとタイムアウト内に終わらない気がしますね.
このように,BigQueryでログデータ以外の集計をする人は実質存在しないかと思いますが,今回のケースではうまくMapReduceの特性を利用することができ,無事高速かつ安価に数千億の組み合わせを試行することができました.
おまけ
BigQueryはスキャン量に応じて課金されると書きました.つまりスキャンしないと無料です.
というわけでこういうことができます.
無限のリソースがあったら何をしますか? とりあえず面倒になったのでモンテカルロ法で円周率でも計算しましょう.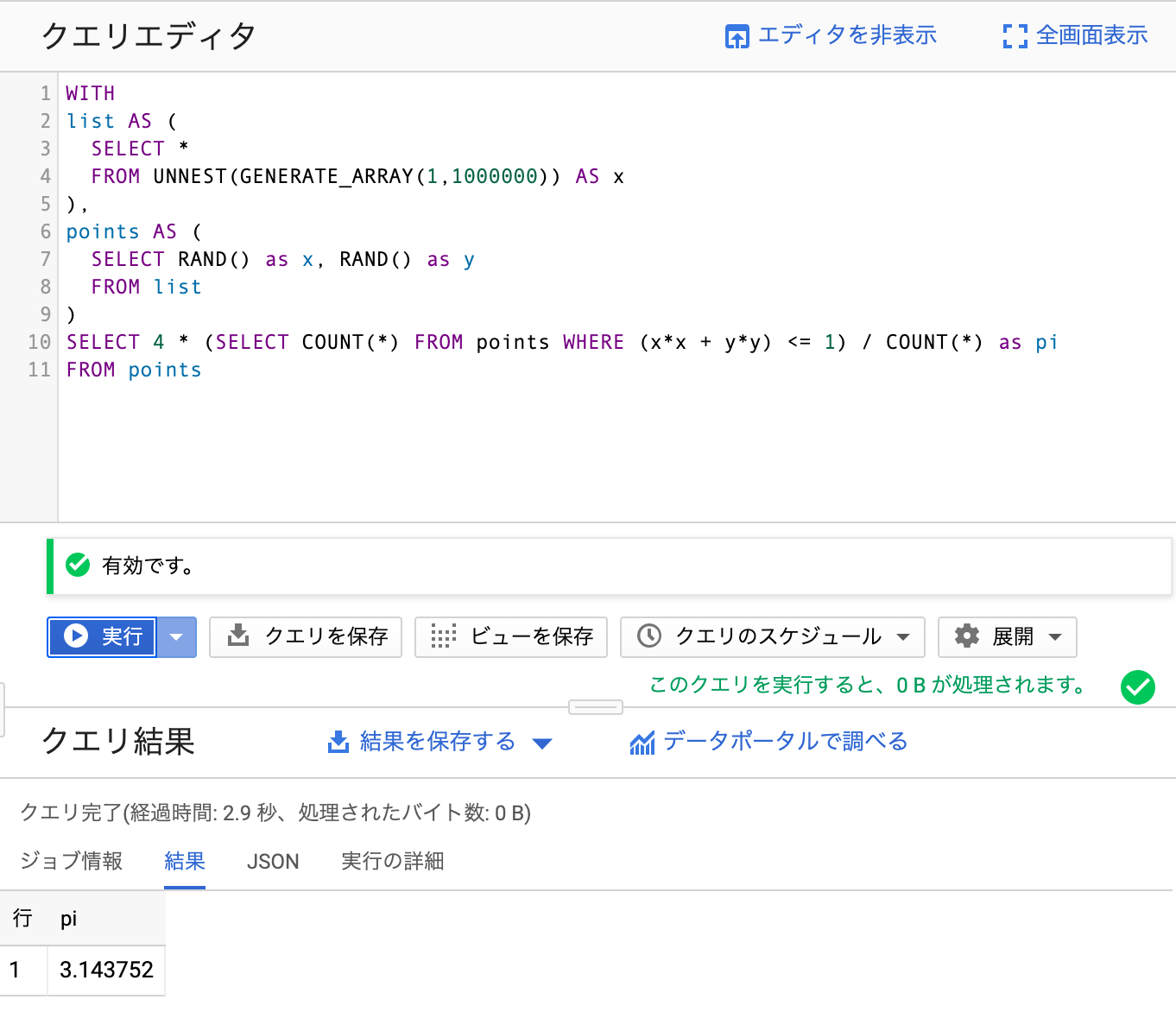 とりあえずできましたが精度が低い……
とりあえずできましたが精度が低い……
 ヌッ
ヌッ
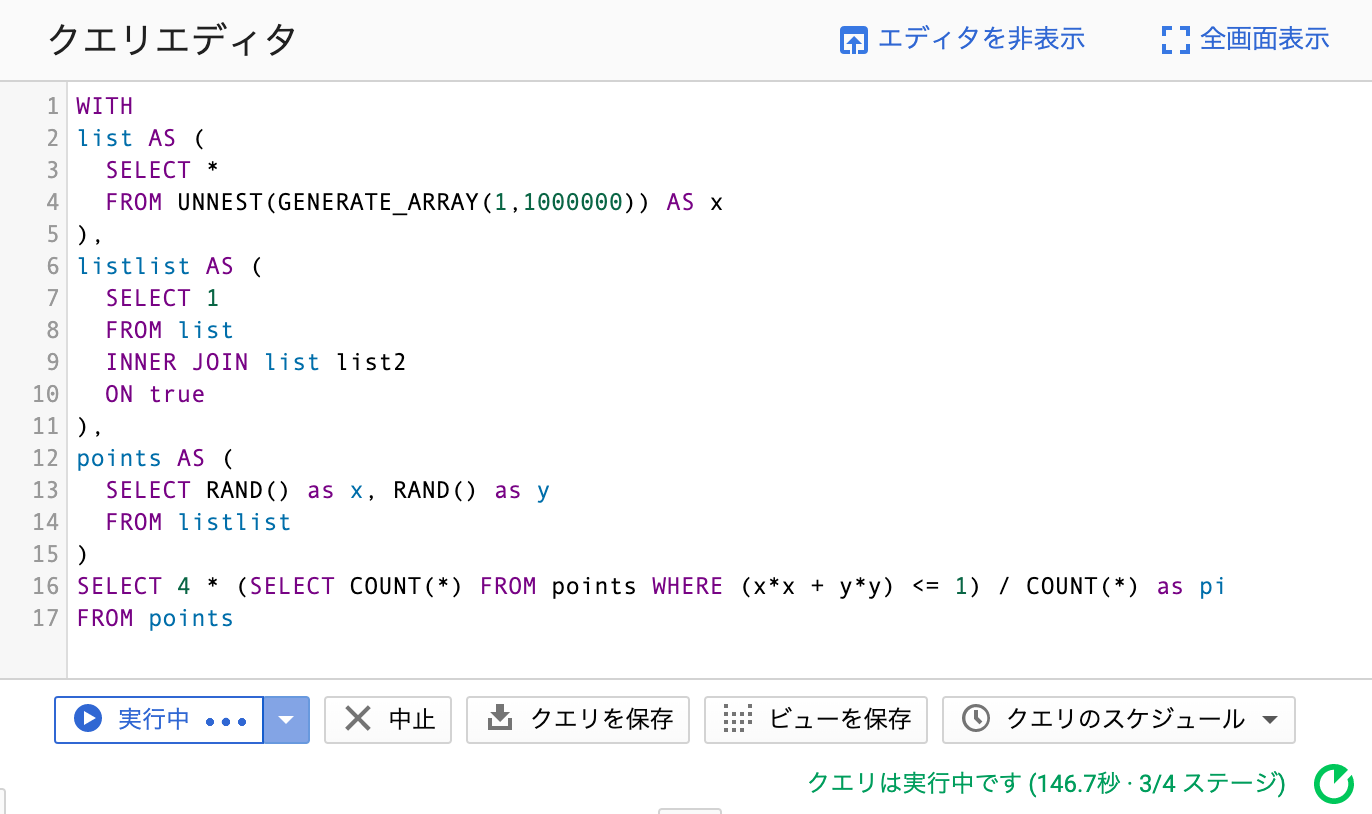 こういうことをしたら終わらなくなってしまったので終わりです.(朝見たらタイムアウトしてました)
こういうことをしたら終わらなくなってしまったので終わりです.(朝見たらタイムアウトしてました)
ちなみにBigQueryはJavaScriptでUDFを書くことができますが,これはこれでタイムアウトやスロット数が別にあり色々大変です.頑張りましょう.
いかがでしたか? ぜひ,皆さんもBigQueryをどんどん活用してください.